Derivative Reuse at Scale: The Core-Exception Model for DITA Structured Content
How to preserve reuse, reduce conditional complexity, and make high-variant publications manageable


Derivative reuse has always been one of the most practical—and one of the most dangerous—forms of content reuse. It begins with a sensible premise: use an existing content component wherever possible, but allow limited changes when the reuse context requires them. In Managing Enterprise Content, Ann Rockley and The Rockley Group distinguish derivative reuse from locked reuse by allowing reused content to change while retaining a relationship to the original content source. In principle, derivative reuse gives content teams the best of both worlds: reuse without forcing false sameness, and variation without losing traceability. [1]
In practice, derivative reuse can become one of the hardest reuse patterns to govern. The problem is not that derivatives exist. The problem is that derivatives often accumulate at the wrong level of granularity. When a sentence, word, phrase, or even a character varies by product, jurisdiction, market, customer, audience, or effective date, authors often respond by embedding more and more conditional logic directly inside the content. Over time, the source becomes less like an authored topic and more like a dense programming artifact. The content may still publish correctly, but it becomes increasingly difficult for authors, reviewers, subject matter experts, translators, and auditors to understand what the source actually says.
This article describes a field-tested approach for managing derivative reuse in high-variant structured content environments: the Core-Exception model for DITA content. The model was developed at NCCI (National Council for Compensation Insurance) to support a complex, state-specific publication with dozens of variants, frequent regulatory updates, strict traceability requirements, and a need to move from a manual exception-compendium model to state-specific publishing at build time. The approach was later presented publicly in the ConVEx conference session On the Road to Boca Raton, delivered in Tempe, Arizona, on May 4, 2022, where the architectural principles, publishing model, and implementation lessons were shared with the broader DITA community. [7][8]
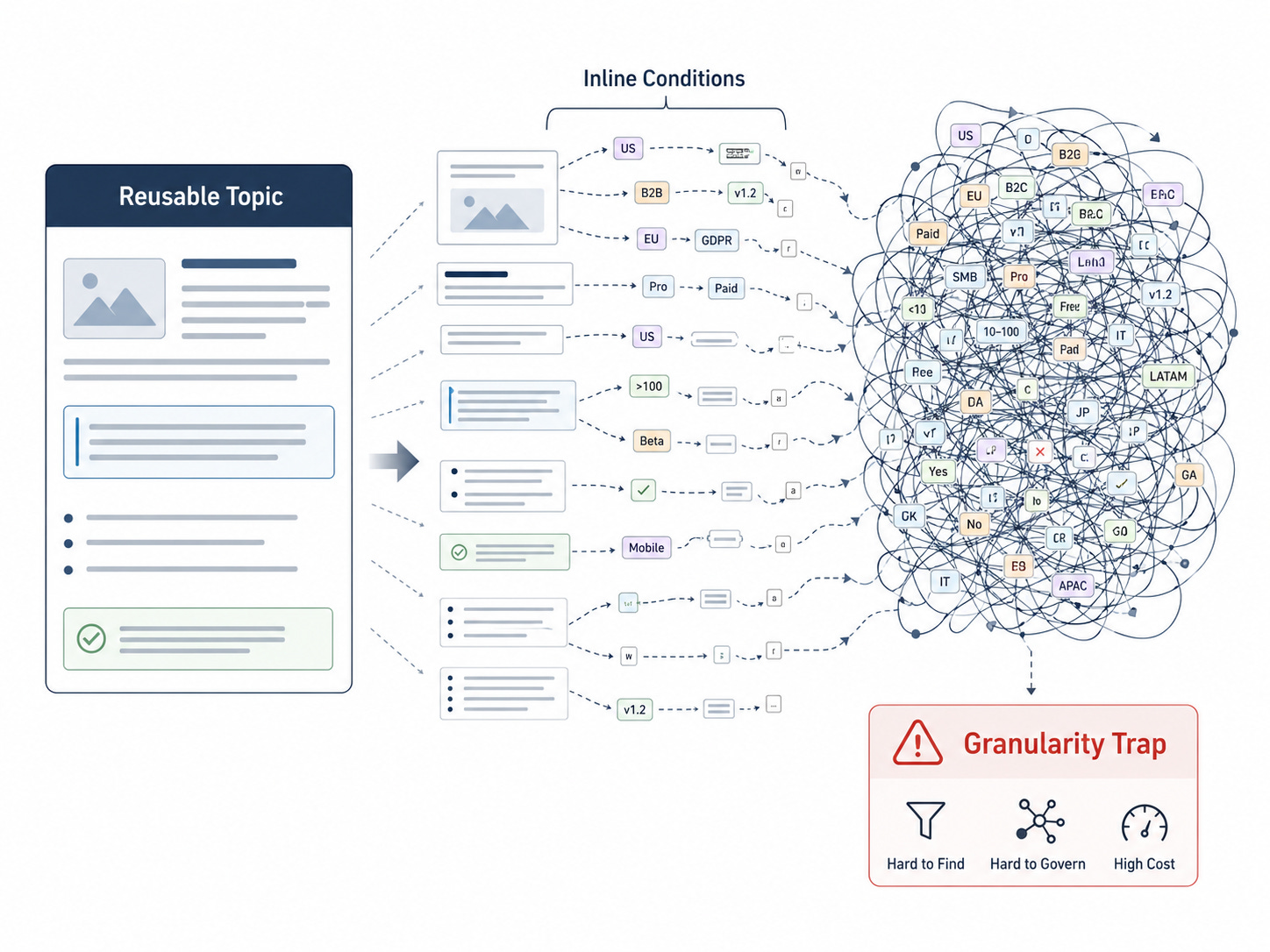
The central idea is simple: stop placing most conditional logic inside the smallest pieces of prose. Instead, move the condition to a managed block of microcontent. One block represents the core rule that applies to most contexts. Zero or more additional blocks represent exceptions that apply to specific contexts. Publishing logic selects an applicable exception when one exists; otherwise, it falls back to the core.
The result is not the elimination of conditional content. It is the disciplined containment of conditional content.
Derivative reuse and the granularity trap
Rockley’s reuse model treats derivative reuse as a legitimate reuse option. A derivative is created when reused content is modified for a new context, while the relationship to the original is preserved. This is valuable when the substance of the content is shared but the expression must differ: spelling, tense, order, emphasis, regional needs, translation, or other contextual variation may justify a derivative. [1]
The difficulty begins when derivative reuse is implemented as a proliferation of tiny conditional fragments. DITA provides powerful mechanisms for profiling and conditional processing. Conditional attributes can be used to include, exclude, or flag content during processing, typically through DITAVAL profiles. [3] These mechanisms are essential for structured publishing. They make it possible to produce multiple deliverables from a common source.
But the same mechanism that works elegantly for a topic, section, paragraph, or reusable component can become fragile when applied repeatedly inside sentences. A phrase conditioned for five audiences may be manageable. A sentence containing conditions for dozens of jurisdictions, effective dates, business rules, and approval states is not. Multiply that pattern across hundreds or thousands of topics and the source becomes difficult to review, difficult to audit, and dangerous to modify.
This is the granularity trap: the content team chooses reuse at a level so small that the management cost begins to exceed the reuse benefit.
At that point, the content architecture needs a different pattern. The question is no longer “Can this word be reused?” The better question is “At what level should variation be governed?”
The NCCI challenge: many variants, high traceability, frequent updates
The NCCI use case involved a large policy-type publication of approximately 800 pages, chunked into numbered sections. The publication had historically been maintained through a manual workflow. A national version of the rules was distributed along with a compendium of state exceptions. Clients then had to use both the national content and the applicable exception material to determine how the rules applied in a particular state. [7]
The publication was not static. It required incremental updates four to six times per year. Some content applied only to certain states. Some content was excluded for certain states. Other content was substantively the same across states but differed in wording. During updates, impacted numbered sections were revised and sent to state regulators for review and approval. Regulators could approve, reject, or approve with changes, and each regulator worked on its own timeline. [7]

Traceability was not optional. The organization needed to track historical, current, approved future, and proposed changes. Some content could be approved but not take effect for six to eighteen months. Some historical versions remained relevant because of court cases, regulatory interpretation, or future product contracts. [7]
In this environment, ordinary conditional processing at the phrase level would have produced an authoring and governance problem. With 37 state clients at the time, and the possibility of more in the future, the content team needed a way to publish state-specific versions without forcing authors to manage dozens of inline conditions inside every affected topic.
As described in On the Road to Boca Raton, the challenge was not simply one of publishing multiple outputs. It was a challenge of balancing reuse, regulatory variation, workflow, version control, and long-term maintainability. The solution was to combine DITA, microcontent, structured writing, and conditional publishing into a more governable architecture. [8]
From topics to microcontent blocks
The first architectural move was to break each numbered section into a block of microcontent. Because workflow, approval, versioning, and traceability needed to be managed in the component content management system, each microcontent block was managed as a topic. [7]
This had an important consequence: the “topic” no longer represented a traditional, full-bodied unit of exposition. Instead, it became a managed block of structured information. The team applied strict writing and titling rules aligned with Precision Content practices and typed each block according to its information purpose: concept, task, process, rule, or reference. [7]
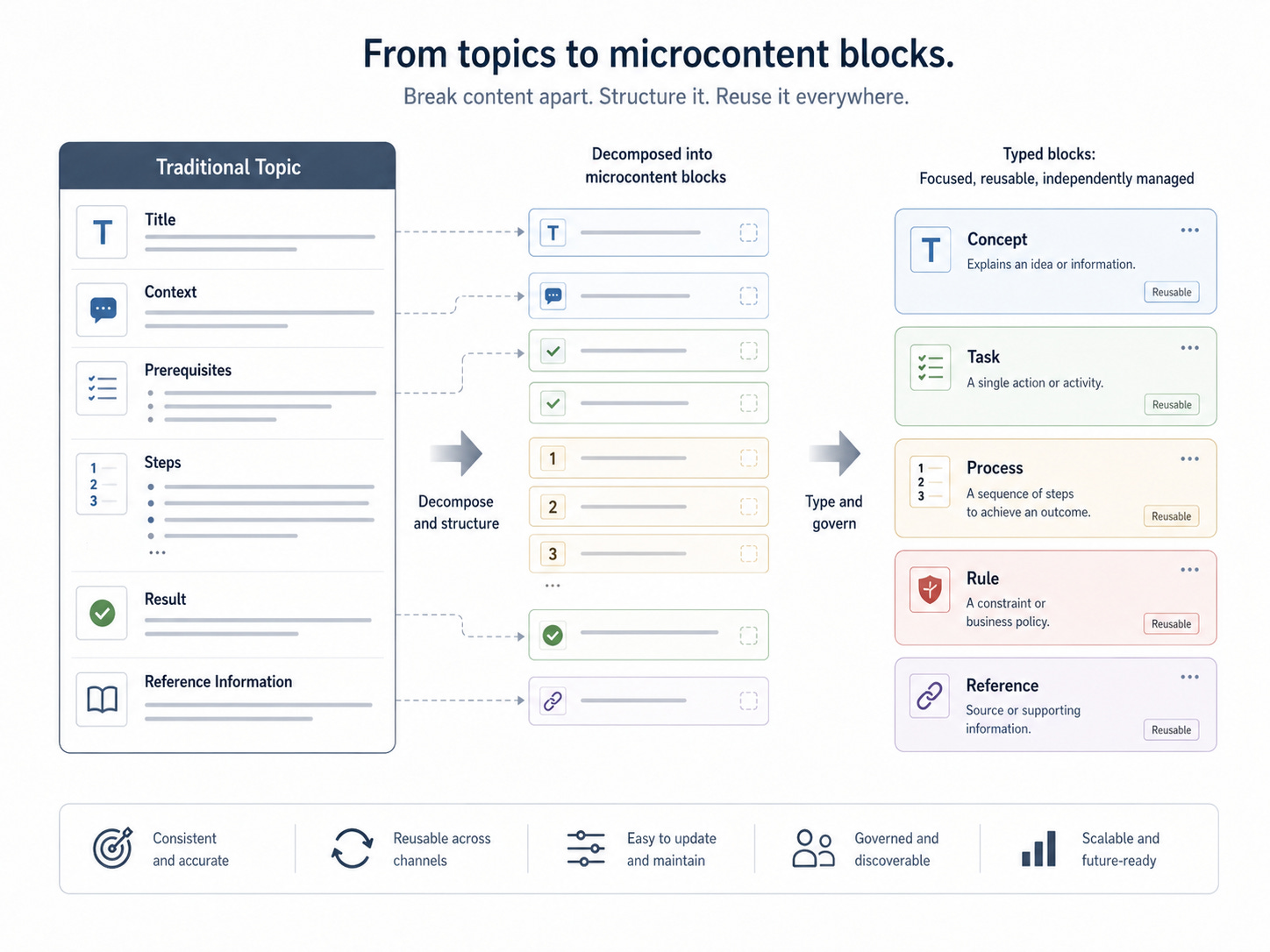
This decision also aligned with the broader logic of information typing in DITA. DITA uses information types such as concept, task, and reference to distinguish different kinds of information and to help authors keep content focused, modular, searchable, navigable, and reusable. [5] Precision Content similarly emphasizes modular, reusable, typed content, organized through repeatable patterns and governed standards. [6]
The key architectural insight was that the standard topic body structure could be too heavy for this use case. Instead of authoring a large task topic with context, prerequisites, steps, results, and related supporting information inside one body, the team decomposed those structures into separately managed microcontent topics. The body was removed from the topic design, and the key semantic structures were moved into a specialization of the topic abstract for each information type. [7]
As discussed in the ConVEx presentation, this shift represented a move away from thinking of topics as documents and toward thinking of topics as governed information assets. The architecture emphasized management, reuse, and traceability at the microcontent level rather than at the publication level. [8]
That move made the block—not the paragraph, phrase, or character—the primary unit of governance.
The Core-Exception model
Once the content was managed as typed microcontent blocks, the team could address derivative reuse at the correct level. Instead of embedding state-specific conditions inside a single block of prose, the team organized each affected section around a Core-Exception pattern. [7]
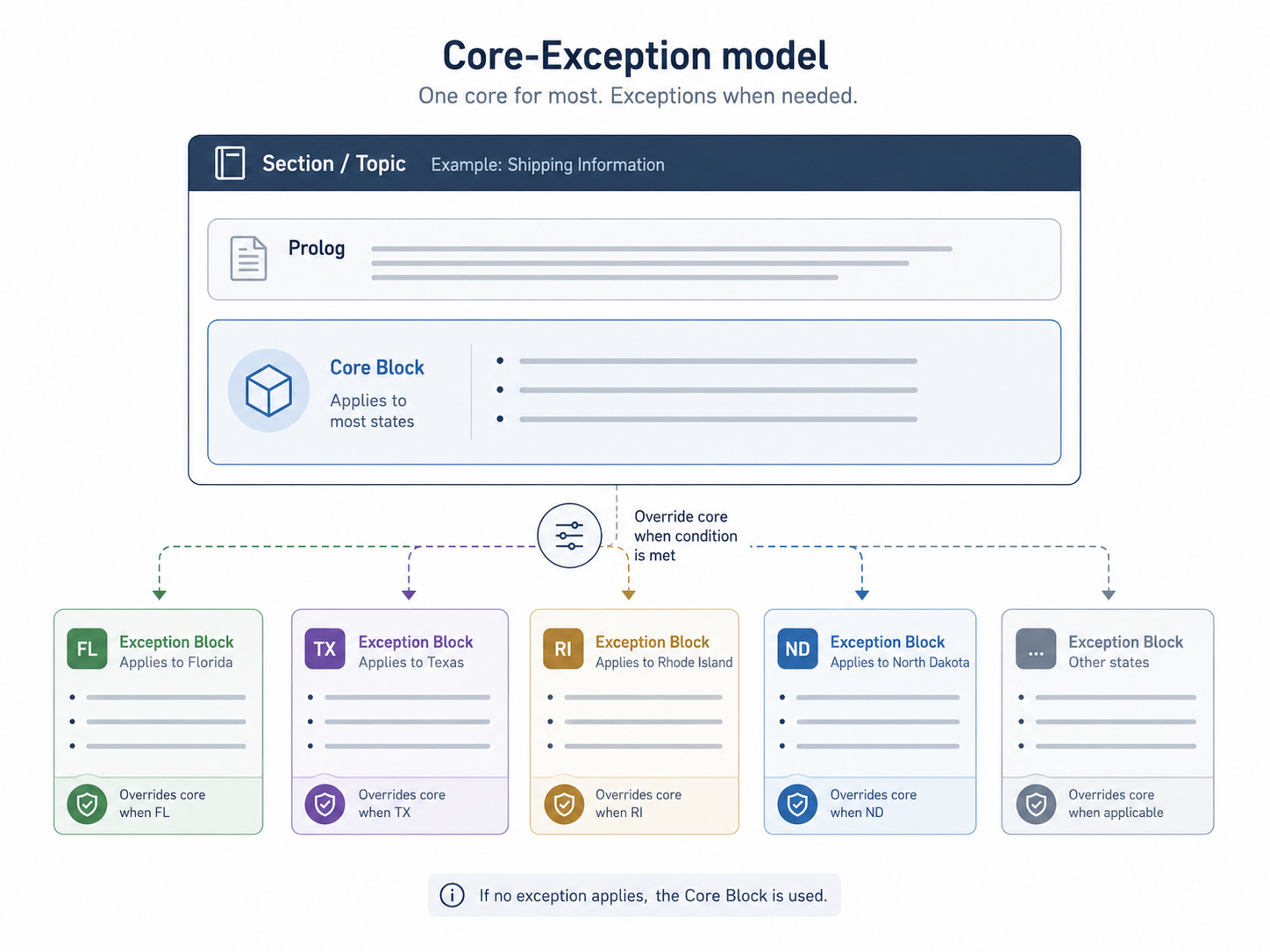
The topic model has three main components:
A typed container topic that holds the title and prolog for the topic blocks.
A Core Block: an embedded microcontent topic block representing the content that applies to the majority of states.
Zero or more Exception Blocks: embedded microcontent topic blocks representing content that applies to one or more specific states.
Each Exception Block carries the conditions for the states to which it applies. The publishing logic looks for exceptions first. If an exception matches the state being published, that exception is included and the Core Block is suppressed. If no exception matches, the Core Block is included. Non-applicable Exception Blocks are excluded. [7]
This changes the authoring model dramatically. Without the Core-Exception model, a topic serving 37 states might require many conditional fragments inside the same source topic. With the Core-Exception model, the topic contains one core expression and only the exceptions that actually exist. If 31 states use the core wording and six states require changes, the author manages one Core Block and six Exception Blocks—not 37 parallel variants. [7]
An important characteristic of the model is that most content requires only a Core Block. Exception Blocks are created only when a meaningful variation exists. As a result, the majority of topics can remain simple and free of conditional complexity, while still supporting extensive variation where necessary.
The ConVEx presentation emphasized that the architecture intentionally treats exceptions as managed content objects rather than conditional fragments. This distinction is critical because it preserves readability, reviewability, and governance while still leveraging DITA’s conditional processing capabilities. [8]
The pattern also scales more gracefully. When a new state is added, the team does not need to touch every topic. Only the sections that differ for that state require new exception blocks. [7]
Exception-first publishing logic
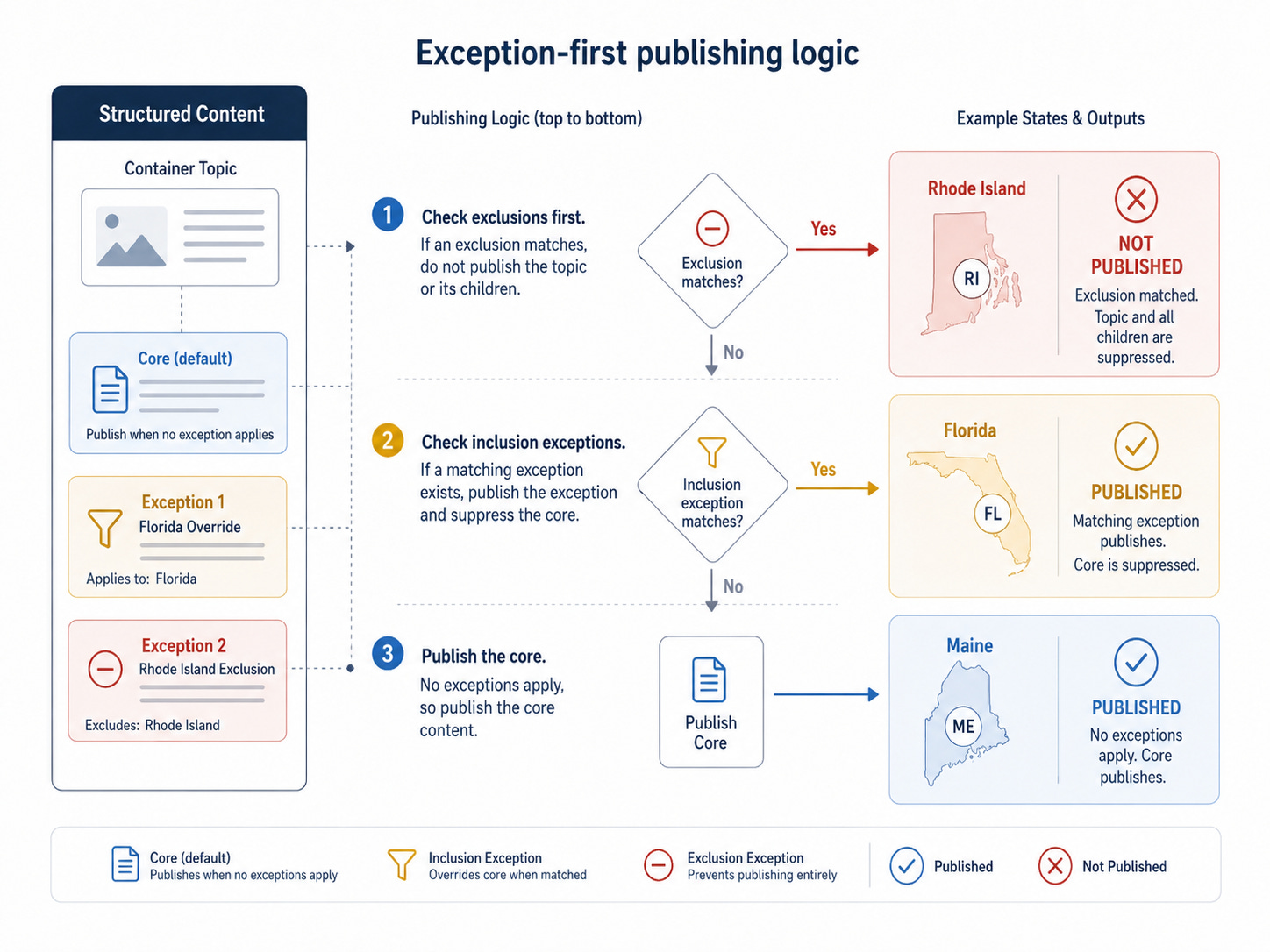
The Core-Exception model depends on clear publishing logic. The processor must evaluate exception applicability before selecting the core. Conceptually, the rule is:
If a matching exception exists, publish the exception, and
Exclude the core and non-matching exceptions.
Else if no matching exception exists, publish the core, and
Exclude all exceptions.
Else if the matching block is marked as not applicable, exclude the topic, and
Exclude its dependent child topics in the map.
This final point is important. The model was extended beyond individual topics into the publication map. If a topic was excluded according to the Core-Exception rules, subsequent child topics in the map under that excluded topic were also excluded. [7]
DITA already supports conditional processing through profiling attributes and DITAVAL, and DITA branch filtering allows filtering conditions to be applied to specific branches of a map rather than only globally. [3][4] The Core-Exception model can be understood as a business architecture and authoring governance layer built on top of such conditional publishing concepts. It gives authors a predictable pattern for where variation belongs and gives publishing logic a deterministic way to resolve that variation.
As demonstrated in On the Road to Boca Raton, the publishing framework effectively creates a controlled inheritance model in which the core serves as the default expression and exceptions override that default only when applicable. This exception-first approach significantly reduces the amount of conditional markup required in source content. [8]
Why the model works
The Core-Exception model works because it separates three concerns that are often tangled together:
the stable identity of the content unit
the default expression of the content, and
the variant expressions required for specific conditions.
The typed container topic preserves the identity of the numbered section. The Core Block represents the default content. Exception Blocks represent controlled deviations from the default. Conditions are attached to the exception blocks rather than scattered throughout the prose.
This makes the content easier to reason about. Reviewers can compare the core and the exception directly. Authors can see whether a state has a true exception or simply inherits the core. Information architects can govern the number and type of exceptions. Publishing engineers can implement a clear fallback rule. Auditors can trace which block appeared in which state-specific output and why.
The model also protects readability in the source. Authors are no longer forced to read a sentence interrupted by multiple conditional fragments. Instead, they read complete, coherent blocks. This is especially important when reviewers are regulators, legal experts, or business stakeholders who must approve the meaning of the content, not the cleverness of the markup.
Relationship to profiling and conditional content
It would be a mistake to present the Core-Exception model as an alternative to DITA profiling. It is better understood as a disciplined use of profiling.
DITA conditional processing is designed to filter or flag content based on processing-time criteria. It allows attributes such as audience, platform, delivery target, props, and specialized props to determine whether elements are included, excluded, or flagged during processing. DITAVAL defines the conditional-processing profile. [3]
The Core-Exception model uses that general capability but changes where the conditions live. Instead of conditioning many small fragments inside a topic, it conditions whole microcontent blocks. This creates a more governable relationship between reuse and variation.
In simple publications, inline profiling may be entirely appropriate. If a short phrase differs for two products, an inline condition may be the simplest solution. But as the number of variants rises, the burden shifts. The question becomes not “Can the tool support this?” but “Can people safely understand, review, and maintain this over time?”
The ConVEx presentation explicitly positioned the Core-Exception model as a response to the limitations of highly granular conditional content. Rather than replacing profiling, the model establishes architectural boundaries around where profiling should be applied and how variation should be represented. [8]
The Core-Exception model is most useful when:
variants are numerous
exceptions are sparse relative to the full variant set
reviewers need to approve complete statements
traceability and effective dating are important
the publication has a stable logical structure
new variants may be added over time, and
differences are meaningful enough to deserve block-level governance.
Change tracking and version baselines
The final major challenge in the NCCI implementation was change tracking. Each state could potentially be associated with different versions of the same section. Some states might have no change between releases. Others might have substantial changes. Some approved changes might not yet be effective. [7]
The Core-Exception model supports this complexity because each microcontent block is managed as a discrete topic in the CCMS. That means the system can version, review, approve, and baseline the Core Block and each Exception Block independently. Rather than treating a large topic as a monolithic unit with hidden internal variation, the architecture exposes the meaningful units of change.
This has several governance benefits. First, it allows the organization to know exactly which block was active for which state at which time. Second, it enables review workflows to focus only on affected blocks. Third, it reduces the risk that a change intended for one state will inadvertently affect another. Fourth, it gives auditors a clearer record of the relationship between source content, approval status, effective date, and published output.
For regulatory and policy content, this is often more important than authoring efficiency. Faster publishing matters, but trustworthy publishing matters more.
Design principles for adopting the Core-Exception model
Organizations considering this pattern should treat it as a content architecture decision, not merely a publishing customization. The following principles are essential.
1. Establish the correct unit of variation
Do not begin by asking how small a reusable element can be. Begin by asking what unit reviewers, approvers, and auditors need to understand. In many high-variant environments, the right unit is not the word or phrase. It is the rule, requirement, procedure, condition, or statement.
2. Make the core explicit
The core is not “everything that remains after exceptions are removed.” It is an authored block that represents the majority case. It should be complete, reviewable, and valid on its own.
3. Treat exceptions as first-class content
An exception should not be a hidden fragment. It should be a managed content block with metadata, ownership, review status, version history, effective dates, and applicability conditions.
4. Use exception-first resolution
Publishing logic must look for applicable exceptions before falling back to the core. Without this rule, exceptions become unpredictable and authors lose confidence in the model.
5. Avoid overusing null exceptions
The NCCI model included triggers to indicate that a block was not applicable as a core or as a state exception. This is powerful, but it should be governed carefully. “Not applicable” is a business statement, not just a publishing trick.
6. Extend the rule to the map when needed
If excluding a parent topic leaves child topics without context, exclusion logic must cascade through the map. Otherwise, the publication may contain orphaned content.
7. Keep authors out of unnecessary logic
The authoring experience should make the model visible without making authors think like build engineers. Authors should understand core, exception, applicability, and effective date. They should not need to mentally simulate the publishing pipeline.
Conclusion: reuse needs architecture
Derivative reuse is not a mistake. It is an inevitable requirement in enterprise content. Real organizations serve multiple products, jurisdictions, channels, audiences, and timeframes. Content must vary.
The danger is unmanaged variation. When derivatives are handled through copy-and-paste, they drift. When they are handled through excessive inline conditioning, they become unreadable. When they are handled as governed, typed, block-level exceptions, they can remain reusable, reviewable, traceable, and publishable.
The Core-Exception model demonstrates that the solution to derivative reuse at scale is not simply “more reuse” or “more conditions.” The solution is better content architecture. By moving variation to the block level, preserving a clear core, treating exceptions as managed microcontent, and resolving applicability at publishing time, organizations can support complex derivative reuse without sacrificing authoring clarity or governance control.
The experience documented by NCCI and shared publicly in On the Road to Boca Raton reinforces a broader lesson for structured content practitioners: successful reuse is not merely a technical capability. It is an architectural discipline that requires thoughtful decisions about granularity, governance, workflow, and publishing behavior. [8]
For high-variant DITA publications, especially in regulated or policy-driven environments, the Core-Exception model offers a practical path forward: write once where content is truly common, vary only where variation is real, and make every exception visible enough to govern.
References
[1] Ann Rockley and The Rockley Group, “Fundamental Concepts of Reuse,” excerpt from Managing Enterprise Content: A Unified Content Strategy.
[2] IBM, “Content Reuse,” technical content practices documentation.
[3] OASIS, DITA 1.3 Architectural Specification, “Conditional processing (profiling).”
[4] OASIS, DITA 1.3 Architectural Specification, “Branch filtering.”
[5] DITA language specification, “Information typing.”
[6] Precision Content, “The Precision Content Method.”
[7] Internal NCCI source document, “Derivative Content Reuse: The Core-Exception Model.”
[8] NCCI, “On the Road to Boca Raton,” presentation delivered at ConVEx Conference, Tempe, Arizona, May 4, 2022.
For more information
Visit our site at www.precisioncontent.com to download our ConVEx presentation and white paper.