Lean RAG Architecture
Optimizing Performance and Reducing Cost Through Standardized Structured Content

Retrieval-augmented generation (RAG) has become the preferred pattern for giving generative AI systems access to fast-changing enterprise knowledge. Instead of retraining a large language model every time a product, policy, feature, or procedure changes, organizations can retrieve current source content at answer time and ask the model to synthesize a response from that evidence. In principle, this gives organizations a practical path to conversational support, intelligent documentation, and just-in-time product assistance.
In practice, many RAG pilots succeed for the wrong reason. A small repository, one product version, and a narrow set of documents can make hallucination rates appear low. As the repository grows to include multiple product versions, regional variants, archived manuals, overlapping procedures, duplicate topics, and inconsistent terminology, the same system becomes harder to trust. The problem is not simply model quality. It is content supply-chain quality.
Lean RAG is the discipline of reducing unnecessary content volume, semantic duplication, and retrieval ambiguity before content reaches the vector store, search index, graph, or prompt. It combines structured source content, governed metadata, semantic chunking, reuse-aware publishing, provenance, and lifecycle control. For technical documentation teams, the most practical path to Lean RAG is often already present in their existing investments: Rich XML for structured source content, a component content management system for governance and lifecycle management, globally-standardized metadata for exchange and discovery, and a publishing pipeline that transforms authoritative source into AI-ready retrieval units.
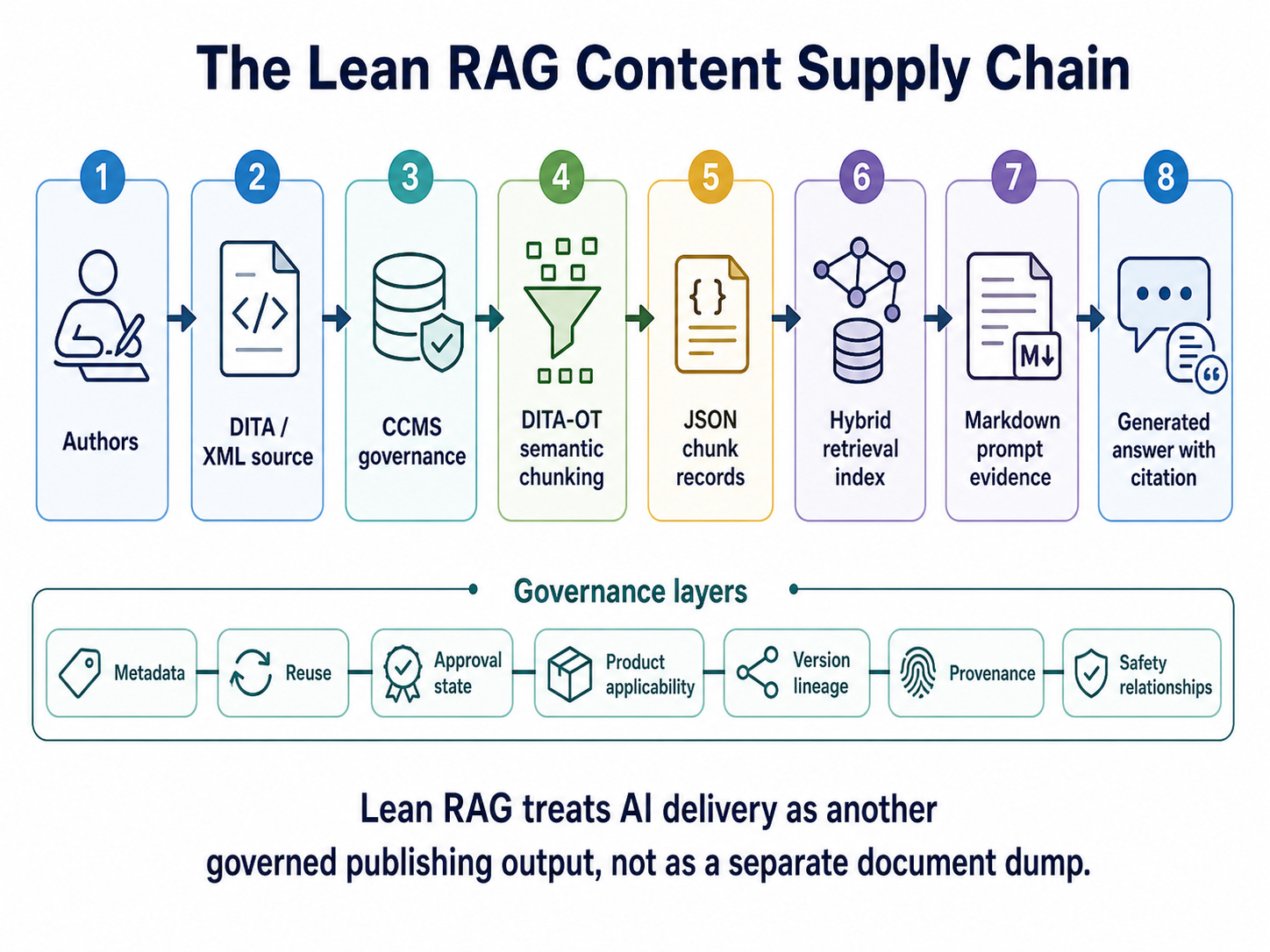
The goal is not to put less useful information into the system. The goal is to put fewer ambiguous copies of consistently chunked information into the system, with enough context, metadata, and lineage for the retrieval layer to select the right evidence at the right time.
Why RAG became the default pattern
RAG emerged as a response to a basic limitation of large language models: even when models contain broad factual knowledge in their parameters, they do not reliably know the current, proprietary, or highly specific facts that enterprise applications require. The original RAG research framed retrieval as a way to combine parametric memory, the model’s learned knowledge, with non-parametric memory, an external index of source documents. This matters especially for knowledge-intensive tasks, where source access, specificity, and provenance are central to trust (Lewis et al., 2020).
For product and service organizations, the appeal is obvious. Product documentation changes constantly. Software features are released, procedures are corrected, warnings are updated, parts are replaced, supported configurations shift, and regulatory language evolves. Training or fine-tuning a model every time these facts change is not a viable operating model. A RAG architecture lets the enterprise keep the model stable while updating the knowledge source underneath it.
This is why RAG is surfacing as the default strategy for chatbots, voice assistants, support copilots, field-service tools, and intelligent delivery portals. It promises current answers without repeated model retraining. It also promises traceability: an answer can be grounded in retrieved source material rather than generated solely from model memory.
But RAG does not solve the content problem by itself. Retrieval only works as well as the evidence available to retrieve.
The hidden failure mode: RAG looks best before it scales
Many RAG projects begin with a small proof of concept. A team loads one manual, one policy set, or one product documentation collection into a vector database. The early results look impressive. The assistant answers recognizable questions. It quotes relevant passages. It appears to avoid hallucinations. Stakeholders conclude that the system is nearly production-ready.
This early success can be misleading.
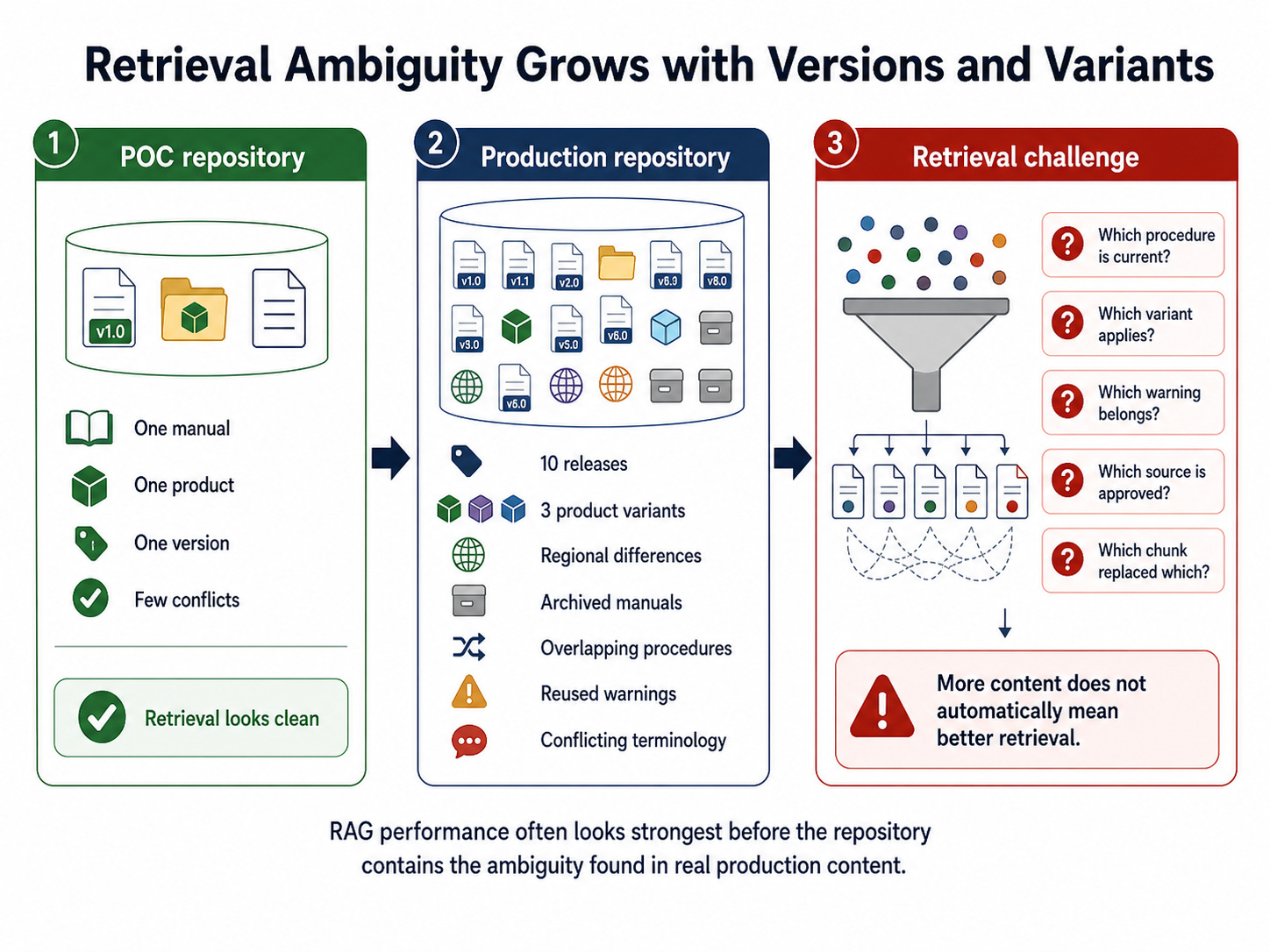
With only one version of a documentation suite in the repository, the retrieval problem is artificially simple. There are fewer near-duplicates, fewer conflicting procedures, fewer obsolete variants, and fewer semantically similar passages competing for selection. As more versions and variations accumulate, the system must distinguish between the current procedure and an outdated one, the domestic version and the European version, the standard product and the premium model, the installation guide and the maintenance guide, the warning that applies to one configuration and the warning that applies to another.
Long context windows do not eliminate this problem. Research on long-context language models shows that models may perform worse when the relevant evidence is buried in the middle of a long input, even when the input technically fits within the context window (Liu et al., 2024). In other words, simply giving the model more content is not the same as giving it the right content.
This is the central argument for Lean RAG: a production RAG system must control ambiguity before retrieval and prompting, not merely compensate for ambiguity afterward.
Lean RAG defined
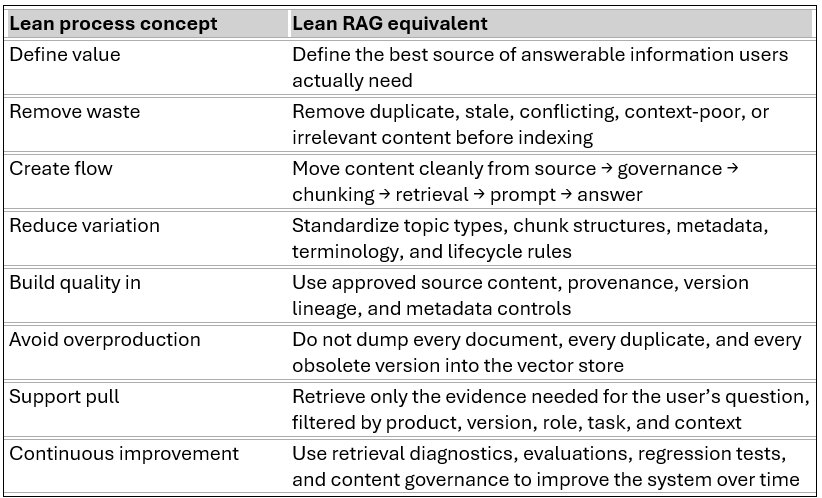
Lean RAG applies lean process principles to the content supply chain: it removes semantic waste, reduces retrieval variation, preserves context, and builds quality into AI-ready content before the model is asked to generate an answer.
A Lean RAG system is not thin. It is disciplined. It contains the right content at the right granularity, with the right metadata, linked to the right source, governed by the right lifecycle controls.
A lean repository has six characteristics:
Authoritative source: retrieved units originate from approved source content, not arbitrary file dumps.
Semantic boundaries: meaningfully labelled chunks defining expressions of intent such as tasks, warnings, error codes, prerequisites, and reference facts.
Context preservation: small units retain enough surrounding context to remain intelligible outside the page where they were authored.
Metadata control: retrieval can filter or rank by product, version, audience, lifecycle phase, component, information type, and safety relevance.
Lineage and provenance: every answerable unit can be traced back to its source, version, publication, and approval state.
Incremental update: changed content can be reprocessed without duplicating every unchanged unit across every publication or product release.
Lean RAG is therefore not only an AI architecture. It is a content operations model.
Start with the source content
The two most important factors in RAG quality are the source content and the system used to manage that content. Models matter. Embeddings matter. Vector databases, re-rankers, graph retrieval, and prompt patterns all matter. But none of them can reliably compensate for content that is duplicated, inconsistent, stale, context-poor, or unmanaged.
For best results, enterprise content needs to be lean and structured before it enters the RAG pipeline. It should be written in focused units, governed by standards, enriched with contextual metadata, and maintained as reusable components rather than uncontrolled files. Word documents, PDFs, and unmanaged Markdown pages can be useful delivery formats, but they are weak source formats for large-scale RAG governance. They often hide structure, flatten metadata, obscure reuse, and make it difficult to maintain referential integrity across publications and variants.
The CCMS as the control plane for RAG
A component content management system (CCMS) is not merely a repository for documentation files. In a Lean RAG architecture, the CCMS becomes the control plane for the content supply chain.
A CCMS can manage reusable topics and fragments, workflow states, approvals, version history, product applicability, publication maps, conditional processing, metadata inheritance, and relationships among content units. These are not peripheral features. They are the exact controls that a RAG system needs in order to avoid retrieving the wrong information.
Systems that treat documents as binary objects cannot easily see inside the content to manage metadata, reuse, lineage, or semantic relationships. A code repository or document management system may provide version control at the file level, but file-level versioning is not the same as content-unit governance. Code repositories lack the ability to preserve referential integrity of link and dependencies. A RAG system needs to know whether a procedure is approved, which product variant it applies to, whether it replaced an older procedure, which warnings must travel with it, and which publication contexts contain it.
The CCMS houses the single source of truth for product and service information. The RAG repository should be a governed publication target, not a shadow content store. RAG output becomes another delivery target along with any number of other channels.
Why DITA is a strong source model for Lean RAG
DITA was created for topic-based, information-typed, reusable technical content. Its core building blocks are topics and maps, and its architecture supports metadata, content reuse, conditional processing, and structured relationships. The OASIS specification describes topics and maps as the basic building blocks of DITA, with metadata available on maps, topics, and elements to support reuse and conditional publishing (OASIS DITA Technical Committee, 2010; OASIS DITA 1.3, 2015/2018).
This makes DITA unusually well aligned with the needs of RAG, even though DITA predates modern generative AI. DITA’s value comes from several properties that map directly to AI retrieval needs:
Topics define meaningful boundaries. A topic is already a candidate retrieval unit because it is designed to be coherent and reusable.
Information typing expresses intent. Task, concept, reference, troubleshooting, and other specialized structures help distinguish what a unit is meant to do.
Maps preserve publication context. A topic can be reused in multiple outputs while the map supplies structure, sequence, and product scope.
Metadata supports filtering and applicability. Audience, product, platform, lifecycle phase, and other attributes can guide retrieval.
Reuse reduces duplication. A shared topic can remain one authoritative object even when it appears in many publications.
Specialization supports enterprise semantics. Organizations can define structures and constraints that reflect their products and domains.
This is why content that was originally designed for human cognition can become valuable for machine cognition. DITA’s topic boundaries, information types, and metadata are not just publishing conveniences. They are retrieval signals.
XML ingestion challenges
DITA XML is an excellent source format, but it is not usually the best format to hand directly to a language model as prompt evidence. DITA was designed for structured authoring, reuse, specialization, and multichannel publishing. A RAG pipeline needs something different: readable, context-rich, deduplicated retrieval units that can be ranked, filtered, cited, and assembled into reliable answers.
Content reuse is one of DITA’s greatest strengths, but it creates ingestion challenges. Topics, fragments, and phrases may appear in many outputs through conrefs, keyrefs, maps, and conditional processing. If every rendered instance is indexed as independent evidence, the retrieval system may treat repeated text as more important than it really is. The problem is not reuse itself; the problem is unmanaged reuse in the retrieval layer.
Preparing DITA XML for Lean RAG
A Lean RAG pipeline should rationalize reuse before indexing. Topic-level and chunk-level reuse should be deduplicated in the repository, while metadata records each location, product, variant, or deliverable where the chunk is reused. This preserves the value of reuse without allowing repetition to distort retrieval ranking or answer generation.
Phrase-level reuse requires a different approach. Product names, feature names, variant labels, and other key-based terms may resolve differently across maps or versions. These resolved values should be preserved in the rendered Markdown and added to the search thesaurus or lexical index as aliases, deprecated terms, or variant-specific terms. This helps users retrieve the right chunk even when product terminology changes.
Much of DITA’s semantic markup should be stripped away. Relevant markup should be transformed into explicit retrieval metadata where it improves filtering, ranking, or answer assembly. Topic type, task structure, product applicability, lifecycle phase, audience, component, variant, and safety information can all become useful metadata fields. The readable content itself should be rendered as clean Markdown, preserving headings, lists, procedures, tables, and warnings where formatting carries meaning.
Transform source DITA into AI-ready retrieval units
The goal is to transform DITA into AI-ready evidence: deduplicated where reuse could mislead retrieval, enriched where semantic context improves ranking, rendered where structure helps the model read, and preserved through metadata where DITA’s original semantics matter.
A Lean RAG pipeline should treat RAG delivery as a publishing output. Just as the same DITA source can be transformed into HTML, PDF, help systems, or training materials, it can also be transformed into AI-ready retrieval packages. There is no need to connect to content repositories via APIs when it can be optimized by the publishing system.
The DITA Open Toolkit already provides an extensible transformation architecture for converting DITA maps and topics into deliverable formats. In a Lean RAG model, a DITA-OT plug-in can generate semantically chunked, metadata-enriched output for search indexes, vector stores, or graph databases.
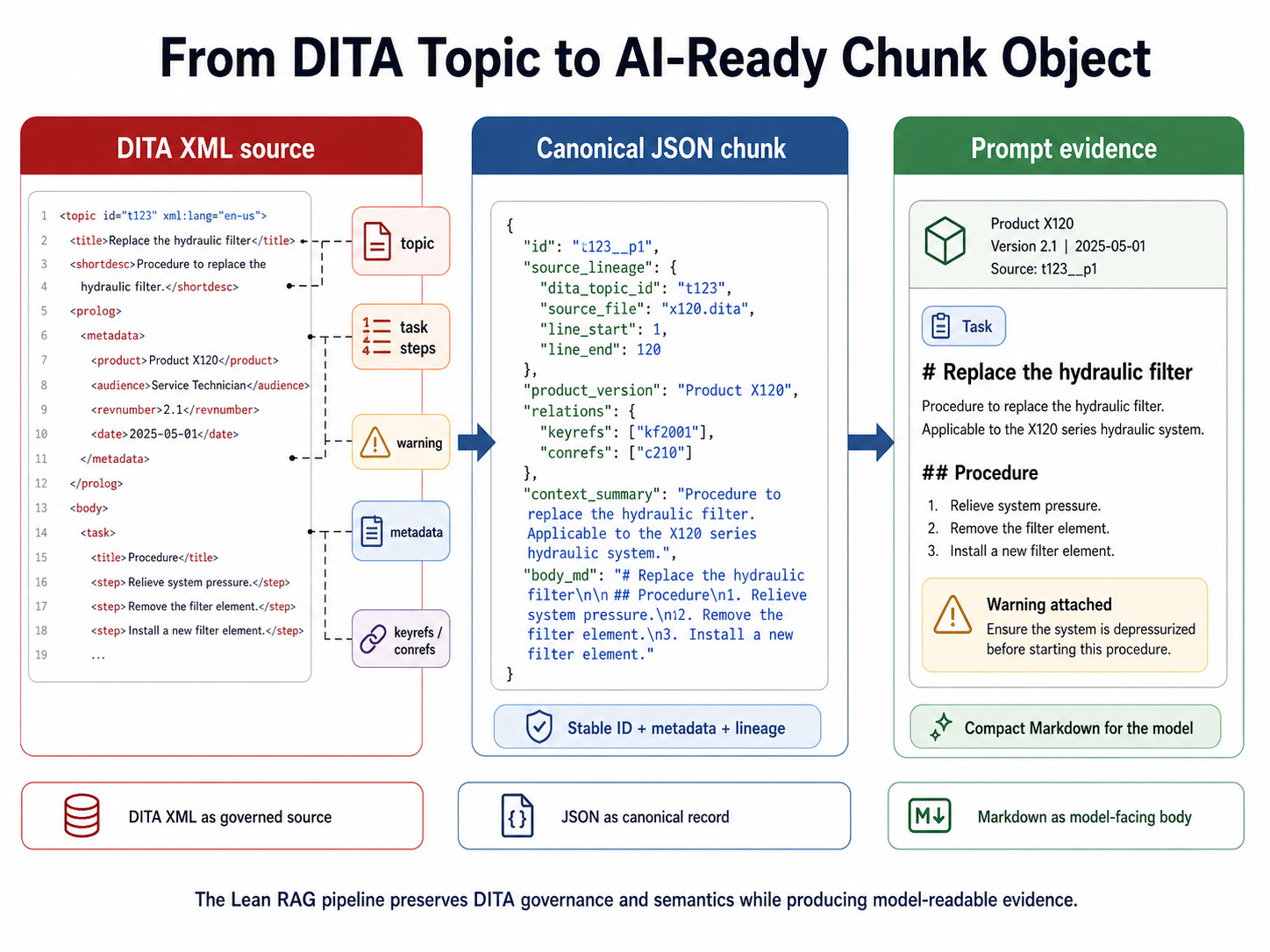
The transformation should not simply strip tags and split text by token count. It should use the source structure to determine the retrieval unit:
A task topic may become one topic-level retrieval unit, with steps preserved in sequence.
A warning may become a required child fragment that must travel with the relevant task.
An error-code table may become row-level reference units, each linked back to the parent table and product context.
A prerequisite may become a reusable fragment attached to multiple procedures.
A troubleshooting topic may become a set of symptom/cause/remedy units, while retaining the parent topic context.
The result should be a canonical chunk object with a stable identifier, source lineage, lifecycle state, applicability metadata, relationships, and a model-facing body. JSON is usually a strong internal representation for this object because it supports validation, schema control, stable IDs, and metadata fields. Markdown is usually better for the human-readable body that the model receives, because headings, lists, steps, and tables remain easy for both humans and models to interpret. Current prompt engineering guidance from OpenAI also supports Markdown for hierarchy and XML-style tags or attributes for clear boundaries and metadata in prompts (OpenAI, 2026).
The practical pattern is therefore hybrid:
DITA XML as governed source
JSON as the canonical chunk and metadata record
Markdown as the model-facing content body
RDF or JSON-LD when standards-based semantic exchange is required
Semantic chunking beats blind chunking
Chunking is one of the most consequential design decisions in any RAG system. Chunks that are too large may contain irrelevant information and increase cost. Chunks that are too small may lose context and become misleading. Microsoft’s RAG guidance emphasizes that effective chunking and search strategies are necessary to optimize relevance, reduce false positives and false negatives, and avoid poor outcomes from chunks that lack sufficient context (Microsoft Azure Architecture Center, 2025).
Blind chunking divides content by character count, token count, paragraph count, page breaks, or generic document layout. Semantic chunking divides content by meaning and function. For structured technical content, semantic chunking can use the authoring model itself: topic type, element role, heading hierarchy, step sequence, warning placement, table structure, relationship metadata, and map context.
Internal semantic chunking tests at Precision Content point in the same direction. In a comparison of four chunking approaches, semantically enriched subtopic chunks were directionally preferred over non-semantic markup-based chunks, topic-level chunks, and non-semantic PDF-based chunking. The study supports the practical hypothesis that semantic enrichment is a promising path for improving RAG for technical documentation.
The key lesson is not that the smallest chunk always wins. It is that chunks need semantic integrity. A procedure step without the procedure title, actor, prerequisites, result, or warning may be too thin. A whole chapter may be too broad. A Lean RAG pipeline should choose the smallest unit that remains safe, coherent, and answerable.
Content standards matter
How the content is written has a material impact on the quality of the response. To create content that can apply relevant chunking consistently at scale, standards need to be in place that govern how information is typed to align with intent or the function of information. Precision Content’s structured authoring methods are constructed to provide guidance on writing for intent to produce viable microcontent for better human cognition and machine processing.
Precision Content defines microcontent as concise blocks of information written, structured, and labeled based on the intended user response for the information. Microcontent must have
Focus – based on a single idea or concept
Function – based on user intent according to defined information types
Structure – use repeatable patterns and language according to intent, and
Context – metadata that can draw microcontent back together.
These principles tie into Lean RAG to eliminate content overlap, redundancy, and consistency for chunking.
Context is not optional
Context loss is one of the most common reasons RAG systems fail. A retrieved fragment may be textually relevant but semantically incomplete. For example, the sentence “Remove the cover” is not useful unless the system knows which product, which procedure, which cover, which conditions, and which safety precautions apply.
Anthropic’s Contextual Retrieval work addresses this issue by prepending a short chunk-specific context summary before embedding and indexing. Anthropic reports that contextual embeddings and contextual BM25 reduced failed retrievals substantially in their evaluation, and that additional reranking improved results further (Anthropic, 2024). The principle is directly applicable to structured technical content: a chunk should carry concise inherited context from the source topic, map, publication, and metadata.
In DITA terms, this means that a retrieval unit may need context from multiple layers including
element or block
topic metadata
map metadata
the publication or product context
system-level metadata
conditional processing values
related warnings and prerequisites, and
version and approval metadata.
This inherited context should not necessarily be dumped into the prompt as a large metadata blob. Too much metadata can become noise. Instead, the pipeline should distinguish between metadata used for filtering and metadata rendered for the model. Filterable metadata can stay in the search index. Prompt-visible metadata should be concise: product, variant, component, information type, audience or role, lifecycle phase, safety relevance, and source date or version when needed.
iiRDS and the role of standardized metadata
DITA provides structure at the source level. iiRDS (Intelligent Information Retrieval and Delivery Standard) provides a standardized metadata vocabulary and exchange model for intelligent information delivery. iiRDS specifies a package format and metadata vocabulary for technical documentation, with RDF as a core expression of metadata and, as of version 1.3, optional JSON-LD serialization (iiRDS Consortium, 2025).
For Lean RAG, iiRDS is valuable because it describes the kinds of contextual distinctions that retrieval systems need to make: document, topic, fragment, product, component, event, lifecycle phase, information type, role or qualification, and relationships among information units. These distinctions can reduce retrieval ambiguity when a repository contains many similar units.
However, metadata should be purposeful. The iiRDS guidance emphasizes that annotation requires significant concept knowledge and should be driven by use cases. A Lean RAG implementation should not “tag everything” simply because fields exist. It should prioritize metadata that changes retrieval behavior:
product and product variant
component or feature
lifecycle phase
information type
audience, role, or qualification
geography or regulatory scope
source publication
effective date and version
safety or compliance relevance, and
relationships such as prerequisite, replacement, version-of, and related procedure.
This metadata can support hybrid retrieval, where vector search handles semantic similarity, keyword search handles exact terms such as part numbers and error codes, and filters enforce applicability.
Provenance and trust
A generated answer is only as trustworthy as the organization’s ability to show where it came from. Provenance is therefore not an afterthought. It is a core requirement for production RAG.
The W3C PROV model defines provenance as information about entities, activities, and agents involved in producing a piece of data or thing, which can be used to assess quality, reliability, or trustworthiness (W3C, 2013). Applied to Lean RAG, provenance means every retrieval unit should be traceable to its source topic, map, publication, version, transformation event, approval state, and publication date.
A strong RAG chunk should answer questions such as:
What source object produced this chunk?
Which publication or product release included it?
Which version replaced it or was replaced by it?
Was it approved, draft, deprecated, or superseded?
Which transformation generated it?
Which metadata was inherited, and from where?
Which warnings, prerequisites, or related fragments must accompany it?
This lineage is essential for audit, troubleshooting, and user trust. It also supports incremental updates: when a source topic changes, the pipeline can reprocess only affected retrieval units and update their metadata without duplicating all unchanged content.
Why Lean RAG reduces cost and saves energy
RAG cost is not only the cost of model tokens. It includes indexing, storage, embedding, reranking, prompt size, evaluation, governance, support escalation, and ongoing maintenance. A bloated repository increases these costs in several ways.
Duplicate and near-duplicate content increases embedding volume and retrieval competition. Overly large chunks increase prompt tokens and may include irrelevant evidence. Overly small chunks increase retrieval calls and require more context reconstruction. Poor metadata increases false positives, which then require reranking, longer prompts, or model reasoning to resolve. Stale content increases risk, which increases the need for human review and escalation.
Lean RAG reduces these costs by keeping one authoritative copy of reusable content, carrying applicability through metadata, and publishing only the retrieval units needed by the target system. The same chunk of content can be valid across multiple publications and product releases without being physically duplicated in the RAG repository. The repository can store one approved unit with metadata that links it to the applicable products, versions, publications, and contexts.
This is the same logic that made structured content and reuse valuable long before generative AI. RAG simply makes the cost of poor content operations more visible.
Governance: The missing layer in many RAG projects
AI governance is often discussed in terms of model behavior, privacy, bias, security, and human oversight. Those concerns are real, but content governance deserves equal attention in enterprise RAG. The NIST AI Risk Management Framework organizes AI risk work around governance, mapping, measurement, and management. Lean RAG applies those same principles to the knowledge supply chain that feeds the model (NIST, 2023).
A governed Lean RAG program should include:
Content standards for topic types, microcontent blocks, terminology, warnings, titles, and metadata.
Source governance through workflows, approvals, review states, and release controls.
Retrieval-unit standards defining when to publish topics, fragments, table rows, examples, troubleshooting units, and safety notes.
Metadata governance defining required fields, inherited fields, controlled vocabularies, and validation rules.
Evaluation practices using test questions, reference answers, pairwise judgments, regression tests, and retrieval diagnostics.
Lifecycle rules for replacing, deprecating, archiving, and removing retrieval units.
Operational ownership across documentation, product, support, engineering, compliance, localization, and AI teams.
A RAG system is not production-ready just because it can answer a test question. It is production-ready when the organization can keep the source content accurate, the retrieval layer current, the metadata trustworthy, and the answer behavior measurable over time.
A practical Lean RAG pipeline
A practical Lean RAG pipeline for technical documentation can be implemented in seven stages.
Authors create and maintain structured source content in DITA or another semantically rich authoring model. They write using clear information types and focused blocks that correspond to user intent.
The CCMS manages reuse, lifecycle state, product applicability, variant conditions, relationships, and publication context.
The publishing pipeline resolves keys, conditions, reusable components, and map-level context so the output reflects the correct publication and product scope.
A semantic chunking Open Toolkit transformation generates retrieval units at the appropriate granularity: topics where the topic is the best answer unit, fragments where reusable microcontent is safe and useful, and row-level units where tables contain independent facts.
The pipeline enriches each unit with inherited metadata, relationship links, provenance, and a concise context summary.
The retrieval layer indexes the units for hybrid retrieval, using vector embeddings, keyword search, metadata filters, and, where useful, graph relationships.
The prompt renderer gives the model compact evidence in Markdown, with clear boundaries and only the metadata needed to answer accurately.
This pipeline allows DITA XML to remain the governed source while each downstream AI system receives the representation it needs.
Conclusion: The future of RAG is a content supply chain issue
RAG is often presented as a model architecture. For enterprise technical content, it is better understood as a content supply-chain problem.
A RAG system retrieves what the organization gives it. If the repository contains uncontrolled documents, duplicate versions, conflicting variants, stale procedures, weak metadata, and context-poor chunks, the model will inherit those weaknesses. If the repository contains structured, approved, semantically coherent, metadata-rich, provenance-aware units, the model has a far better chance of producing accurate, current, and trustworthy answers.
Lean RAG is the bridge between technical communication discipline and generative AI performance. It does not abandon structured authoring principles. It extends them into AI delivery. DITA supplies structure. The CCMS supplies lifecycle control. iiRDS-style metadata supplies machine-readable context. Semantic intent-based chunking supplies answerable units. Provenance supplies trust. Governance supplies durability.
The organizations that succeed with RAG will not be the ones that simply load the most documents into the largest vector database. They will be the ones that treat AI delivery as another output of a governed, lean, intelligent content supply chain.
References
Anthropic. (2024). Introducing Contextual Retrieval. Anthropic Engineering.
DITA Open Toolkit. (2026). DITA Open Toolkit architecture documentation.
iiRDS Consortium. (2025). iiRDS Version 1.3 materials and Guide for the Standardized Use of iiRDS.
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W., Rocktäschel, T., Riedel, S., & Kiela, D. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Advances in Neural Information Processing Systems.
Liu, N. F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., & Liang, P. (2024). Lost in the Middle: How Language Models Use Long Contexts. Transactions of the Association for Computational Linguistics.
Microsoft Azure Architecture Center. (2025). Develop a RAG solution: Chunking phase. Microsoft Learn.
National Institute of Standards and Technology. (2023). Artificial Intelligence Risk Management Framework (AI RMF 1.0).
OASIS DITA Technical Committee. (2010). Darwin Information Typing Architecture (DITA) Version 1.2: Architectural Specification. OASIS.
OASIS DITA Technical Committee. (2015/2018). Darwin Information Typing Architecture (DITA) Version 1.3. OASIS.
OpenAI. (2026). Prompt engineering, retrieval, and structured output guidance. OpenAI Developers.
World Wide Web Consortium. (2013). PROV-DM: The PROV Data Model. W3C Recommendation.